Data consistency一致性 in microservices微服务architecture架构
In microservices, one logically atomic operation原子操作 can frequently span 跨越multiple microservices. Even a monolithic单片的 system might use multiple databases or messaging solutions. With several independent data storage solutions数据存储方案, we risk inconsistent data if one of the distributed process participants fails — such as charging收费 a customer without placing the order or not notifying 通知the customer that the order succeeded. In this article, I’d like to share some of the techniques I’ve learned for making data between microservices eventually consistent最终一致性
在微服务中,逻辑上的原子操作经常跨越多个微服务。即使是单体应用架构下,也可能使用多个数据库或消息队列解决方案。使用几种独立的数据存储解决方案,如果分布式流程参与者之一失败,我们将面临数据不一致的风险,例如,向客户收费而不下订单,或者不通知客户订单成功。在本文中,我想分享一些在微服务体系架构下确保数据最终一致的技术。
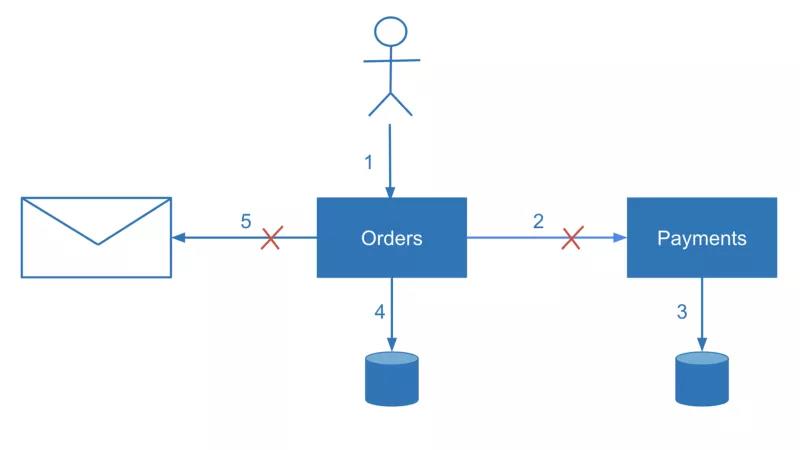
Why is it so challenging 挑战性to achieve this? As long as 只要we have multiple places where the data is stored (which are not in a single database), consistency is not solved automatically自动的 and engineers need to take care of consistency while designing the system. For now, in my opinion, the industry 行业doesn’t yet have a widely known solution for updating data atomically in multiple different data sources — and we probably shouldn’t wait for one to be available soon.
为什么要做到这一点如此具有挑战性?只要我们有多个存储数据的地方(而不是在一个数据库中),一致性就不会自动解决,工程师在设计系统时就需要考虑一致性。就目前而言,在我看来,业界还没有一个广为人知的解决方案来原子化地更新多个不同数据源中的数据,而且在可预见的将来,也不会有一个很快就可以使用的解决方案。
One attempt to solve this problem in an automated and hassle-free 无忧manner 方式is the XA protocol 协议implementing实现 the two-phase commit (2PC两阶段提交) pattern. But in modern现代的 high-scale applications高可用服务 (especially in a cloud environment云环境), 2PC doesn’t seem to perform so well. To eliminate消除 the disadvantages of 2PC, we have to trade交易,交换 ACID for BASE and cover覆盖 consistency concerns ourselves in different ways depending on the requirements.
以自动化和省力的方式解决这个问题的一个尝试是以XA协议实现两阶段提交(2PC)模式但是在现代大规模应用程序中(特别是在云环境中),2PC的性能似乎不太好。为了消除2PC的缺点,我们必须牺牲ACID来遵循BASE原则,并根据需要采用不同的方式来满足数据一致性的要求
SAGA模式
The most well-known way of handling处理 consistency concerns忧虑,问题 in multiple microservices is the Saga Pattern. You may treat 看待Sagas as application-level distributed coordination 协调of multiple transactions. Depending on the use-case and requirements, you optimize 优化your own Saga implementation.实现 In contrast相反, the XA protocol协议 tries to cover all the scenarios场景. The Saga Pattern is also not new. It was known and used in ESB and SOA architectures in the past. Finally, it successfully transitioned to the microservices world. Each atomic business operation 原子操作that spans multiple services might consist of由…组成 multiple transactions on a technical level. The key idea of the Saga Pattern is to be able to roll back one of the individual transactions. As we know, rollback is not possible for already committed individual transactions out of the box. But this is achieved by invoking a compensation action补偿措施 — by introducing a “Cancel” operation.
在多个微服务中处理一致性问题的最著名方法是SAGA模式可以将SAGA视为多个事务的应用程序级分布式协调机制。根据用例和需求,可以优化自己的SAGA实现,XA协议正相反,试图以通用方案涵盖所有的场景。SAGA模式也并非什么新概念。它过去在ESB和SOA体系结构中就得到认知和使用,并最终成功地向微服务世界过渡。跨多个服务的每个原子业务操作可能由一个技术级别上的多个事务组成。Saga模式的关键思想是能够回滚单个事务。正如我们所知道的,对于已经提交的单个事务来说,回滚是不可能的。但通过调用补偿行动,即通过引入“Cancel”操作可以变相的实现这一点。
In addition to cancelation取消, you should consider making your service idempotent幂等, so you can retry or restart certain operations in case of failures. Failures should be monitored and reaction to failures should be proactive主动的.
除了取消操作之外,还需要考虑使服务的幂等性,以便在发生故障时可以重新尝试或重新启动某些操作。应该对失败进行监测,对失败的反应应该积极主动。
Reconciliation 对账
What if如果 in the middle of the process the system responsible for calling a compensation action crashes or restarts. In this case, the user may receive an error message and the compensation logic should be triggered or — when processing asynchronous 异步user requests, the execution logic执行逻辑 should be resumed恢复,重新开始.
如果在进程中间,负责调用补偿操作的系统崩溃或重新启动怎么办?在这种情况下,用户可能会收到错误消息,触发补偿逻辑,在处理异步用户请求时,重试执行逻辑。
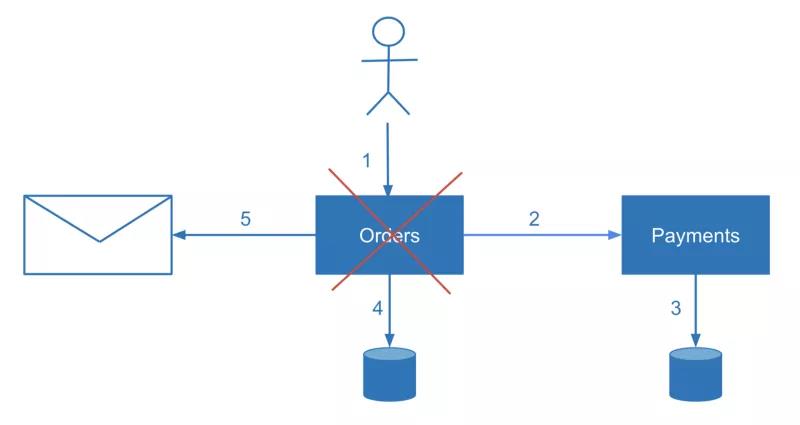
To find crashed崩溃 transactions and resume operation or apply compensation, we need to reconcile 协调data from multiple services. Reconciliation is a technique familiar to engineers who have worked in the financial domain. Did you ever wonder how banks make sure your money transfer didn’t get lost or how money transfer happens between two different banks in general? The quick answer is reconciliation.
要查找崩溃的事务并恢复操作或应用补偿,我们需要协调来自多个服务的数据。对从事金融领域工作的工程师来说,对账是一种熟悉的技术。你有没有想过,银行如何确保你的汇款不会丢失,或者在两家不同的银行之间是如何发生转账的?快速的答案是对账。
In accounting会计, reconciliation is the process of ensuring that two sets of records (usually the balances余额 of two accounts) are in agreement一致. Reconciliation is used to ensure that the money leaving an account matches the actual money spent. This is done by making sure the balances match at the end of a particular accounting period
在会计领域,对账是确保两套记录(通常是两个账户的余额)一致的过程。对账手段确保离开帐户的钱与实际花费的钱相符。这是通过确保在特定会计期间结束时的余额匹配来实现的。
Coming back to microservices, using the same principle we can reconcile data from multiple services on some action trigger. Actions could be triggered on a scheduled basis or by a monitoring system when failure is detected检测到. The simplest approach途径方法 is to run a record-by-record comparison逐条比较. This process could be optimized by comparing aggregated values. In this case, one of the systems will be a source of truth for each record.
回到微服务方面,使用相同的理念,我们可以在某些操作触发器上协调来自多个服务的数据。可以按计划执行对账操作,也可以在检测到出状况时,由监视系统触发相关操作。最简单的方法是按记录逐条进行比较,当然,也可以通过比较汇总值来优化此过程。在这种情况下,某个系统的数据将成为基准数据来对每条数据进行比对。
Event log 日志事件
Imagine设想 multistep transactions多重事物. How to determine during reconciliation which transactions might have failed and which steps have failed? One solution is to check the status of each transaction. In some cases, this functionality is not available可达的,可用的 (imagine a stateless mail service that sends email or produces other kinds of messages). In some other cases场景案例, you might want to get immediate visibility on the transaction state, especially in complex scenarios复杂场景 with many steps. For example, a multistep order with booking flights, hotels, and transfers.
再来讨论多步事务的情况。如何确定在对账过程中哪些事务在哪些环节上失败了?一种解决方案是检查每个事务的状态。在某些情况下,这个方法并不适用(比如无状态的邮件服务发送电子邮件或生成其他类型的消息)。在其他一些情况下,我们可能希望获得事务状态的即时可见性(也就是实时知晓其当前的状态),特别是在具有多个步骤的复杂场景中。例如,一个多步骤的订单,包括预订航班、酒店和转乘。
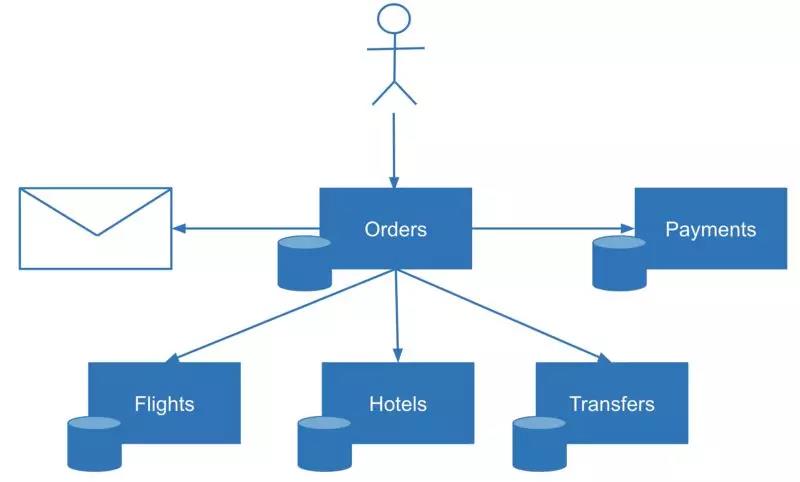
In these situations, an event log can help. Logging is a simple but powerful technique. Many distributed systems rely on logs. “Write-ahead logging” is how databases achieve transactional behavior or maintain consistency between replicas internally内部的. The same technique could be applied to microservices design. Before making an actual data change, the service writes a log entry about its intent意图 to make a change. In practice, the event log could be a table or a collection inside a database owned by the coordinating协调 service.
在这种情况下,事件日志可能会有所帮助。日志记录是一种简单但功能强大的技术。许多分布式系统依赖日志。“预写日志“就是在数据库内部实现事务行为或保持副本之间的一致性的方法。同样的技术也可以应用于微服务设计。在进行实际的数据更改之前,服务会编写一个日志条目,对即将实施的更改操作进行说明。实现方式上,事件日志是从属于协调服务的数据库中的表或集合。
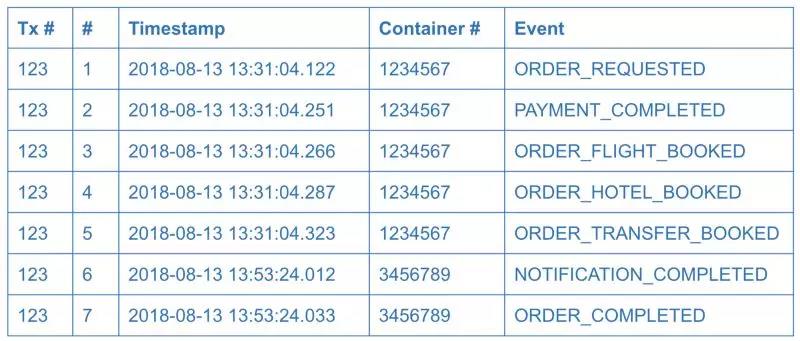
The event log could be used not only to resume transaction processing but also to provide visibility to system users, customers, or to the support team. However, in simple scenarios a service log might be redundant多余的 and status endpoints 状态节点or status fields be enough.
事件日志不仅可用于恢复事务处理,还可用于向系统用户、客户或支持团队提供可见性。但是,在简单的场景中,服务日志可能是多余的,状态端点或状态字段就足够了。
Orchestration vs. choreography 编曲和编舞
By this point, you might think sagas are only a part of orchestration scenarios. But sagas can be used in choreography as well, where each microservice knows only a part of the process. Sagas include the knowledge on handling both positive正向积极 and negative负向,否定 flows of distributed transaction. In choreography, each of the distributed transaction participants has this kind of knowledge.
至此,您可能会认为SAGA只适用于编曲场景的一部分。但是SAGA也可以用于编舞场景,每个微服务只知道其中的一部分。SAGA内置了处理分布式事务的正向流和负向流的相关机制。在编舞场景中,每个分布式事务参与者都有这样的知识。
Single-write with events
单一写入事件
The consistency solutions described so far到目前为止 are not easy. They are indeed确实 complex. But there is a simpler way: modifying a single datasource at a time.Instead of changing the state of the service and emitting触发 the event in one process, we could separate those two steps.
到目前为止,上述的一致性解决方案并不容易。它们确实很复杂。但有一种更简单的方法:每次只修改一个数据源。我们可以将更改服务的状态并发出事件这两个步骤分开,而不是在一个进程中处理。
Change-first “变更优先”原则
In a main business operation, we modify our own state of the service while a separate process reliably 可靠地captures the change and produces 生成the event. This technique is known as Change Data Capture (CDC). Some of the technologies implementing this approach are Kafka Connect or Debezium.
在主要业务操作中,我们可以修改自己服务的状态,同时由一个单独的进程捕获相关变更并生成事件。这种技术被称为变更数据捕获(CDC)。实现此方法的一些技术包括 Kafka Connect或 Debezium。
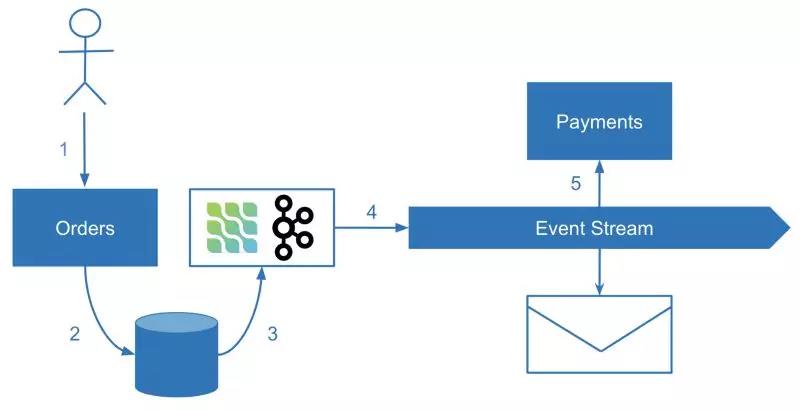
However, sometimes no specific framework is required. Some databases offer a friendly way to tail 跟踪their operations log, such as MongoDB Oplog. If there is no such functionality in the database, changes can be polled by timestamp or queried with the last processed ID for immutable records. The key to avoiding inconsistency is making the data change notification a separate process. The database record is in this case the single source of truth. A change is only captured if it happened in the first place.
然而,有时不需要特定的框架来进行处理。一些数据库提供了一种跟踪操作日志的友好方法,如MongoDB Oplog。如果数据库中没有这样的功能,则可以使用时间戳轮询更改,或者使用最后处理的ID查询不可变记录。避免不一致的关键是使数据更改通知成为一个单独的进程。数据库记录在这种情况下为基准数据。一旦发生数据变更,相关数据即被捕获和记录。
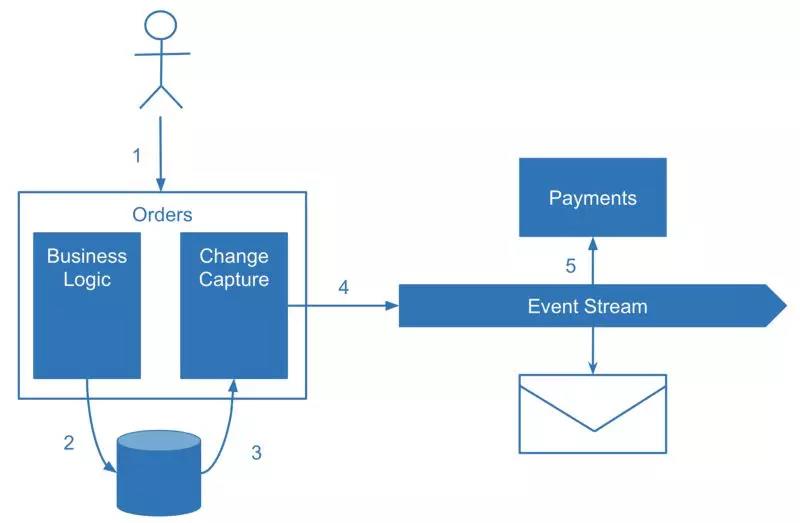
The biggest drawback退税,缺陷 of change data capture is the separation of business logic. Change capture procedures程序 will most likely live in your codebase代码库 separate from the change logic itself — which is inconvenient不方便. The most well-known application of change data capture is domain-agnostic change replication such as sharing data with a data warehouse数仓. For domain events, it’s better to employ a different mechanism机制 such as sending events explicitly显式地,明确的.
变更数据捕获的最大缺点是业务逻辑的分离。更改捕获过程很可能存在于您的代码库中,与更改逻辑本身分离,这是不方便的(所谓的不方便,我的理解,不是指更改捕获过程与业务逻辑的分离,而是指用户需要为每个业务逻辑单独的实现更改捕获逻辑)。最广为人知的更改数据捕获应用场景是领域无关的更改复制,例如通过数据仓库进行数据共享。对于域内的事件,最好使用不同的机制,比如显式地发送事件。
Event-first “事件优先”原则
Let’s look at the single source of truth唯一来源,基础数据 upside down逆向. What if instead of而不是 writing to the database first we trigger an event instead and share it with ourselves and with other services. In this case, the event becomes成为 the single source of truth. This would be a form of event-sourcing where the state of our own service effectively becomes a read model and each event is a write model.
让我们对“基准数据”做一个逆向思考。如果我们不是首先写入数据库,而是先触发一个事件并与我们自己和其他服务共享这个事件呢?在这种情况下,事件成为基准数据。这将是一种 event-sourcing的形态,在这种情况下,服务状态实际上变成了一个读模型,而每个事件都是一个写模型。
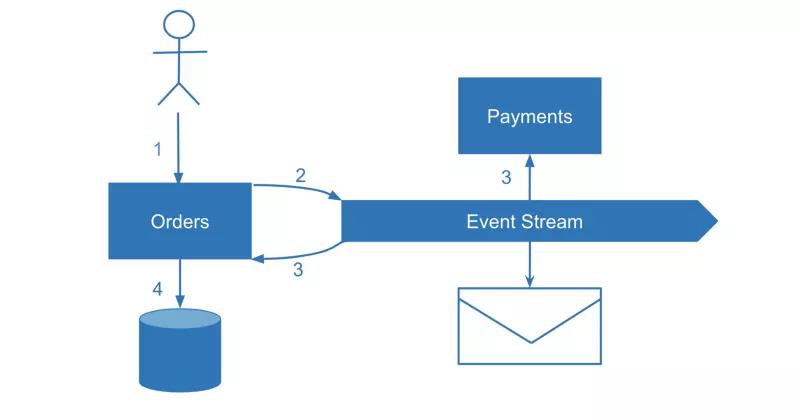
On the one hand, it’s a command query responsibility segregation查询责任分离 (CQRS) pattern模式 where we separate the read and write models, but CQRS by itself doesn’t focus on the most important part of the solution — consuming the events with multiple services.
所以,这也是一种命令查询责任分离(CQRS)模式,将读写模型分离开来,但是CQRS本身并没有关注解决方案中最重要的部分,即如何由多个服务来对事件进行处理。
In contrast, event-driven architectures focus on events consumed by multiple systems but don’t emphasize 强调the fact that events are the only atomic pieces of data update. So I’d like to introduce “event-first” as a name to this approach: updating the internal state of the microservice by emitting a single event — both to our own service and any other interested microservices.
相反,事件驱动体系结构关注多个系统对事件的处理,但不突出强调事件是数据更新的基准数据。所以我想引入 “事件优先”原则作为此方法的名称:通过发出单个事件来更新微服务的内部状态-包括对我们自己的服务和任何其他感兴趣的微服务。
The challenges with an “event-first” approach are also the challenges of CQRS itself. Imagine that before making an order we want to check item availability. What if two instances concurrently receive an order of the same item? Both will concurrently check the inventory in a read model and emit发出,触发 an order event. Without some sort of covering 覆盖scenario we could run into troubles.
采用“事件优先”方法的挑战也是CQRS本身的挑战。想象一下,在下订单之前,我们要检查商品的可用性。如果两个实例同时接收同一项的订单怎么办?两个实例将以读取模型同时检查库存,并触发一个订单事件。如果不解决这个问题,我们可能会遇到麻烦。
The usual way to handle these cases is optimistic乐观 concurrency并发: to place放置 a read model version into the event and ignore it on the consumer side if the read model was already updated on consumer side. The other solution would be using pessimistic悲观 concurrency control, such as creating a lock for an item while we check its availability.
处理这些情况的通常方法是乐观并发:在事件中放置一个读取模型版本,如果已在使用者端更新读取模型,则忽略这个读取操作。另一种解决方案是使用悲观的并发控制,例如在查询项目可用性时为其创建锁。
The other challenge of the “event-first” approach is a challenge of any event-driven architecture — the order of events时间顺序. Processing events in the wrong order by multiple concurrent consumers might give us another kind of consistency issue, for example processing an order of a customer who hasn’t been created yet.
“事件优先”方法的另一个挑战是对任何事件驱动的体系结构的挑战,即事件的顺序。多个并发消费者以错误的顺序处理事件可能会给我们带来另一种一致性问题,例如,处理尚未创建的客户的订单。
Data streaming solutions such as Kafka or AWS Kinesis can guarantee保证 that events related to a single entity will be processed sequentially (such as creating an order for a customer only after the user is created). In Kafka for example, you can partition topics by user ID so that all events related to a single user will be processed by a single consumer assigned to the partition, thus allowing them to be processed sequentially. In contrast, in Message Brokers, message queues have an order but multiple concurrent consumers make message processing in a given order hard, if not impossible甚至不可能. In this case, your could run into concurrency issues.
数据流解决方案(如Kafka或AWS Kinesis)可以保证与单个实体相关的事件将按顺序处理(例如,只在创建用户之后才为客户创建订单)。例如,在Kafka中,您可以通过用户ID对主题进行分区,这样与单个用户相关的所有事件都将由分配给该分区的单个使用者处理,从而允许按顺序处理这些事件。相反,在使用消息代理机制时,消息队列虽然有其固有的执行顺序,但多个并发使用者使得按给定顺序进行消息处理非常困难,甚至不可能。这样就可能会遇到并发问题。
In practice, an “event-first” approach is hard to implement in scenarios when linearizability线性化 is required or in scenarios with many data constraints约束 such as uniqueness checks. But it really shines 发光,大放异彩in other scenarios. However, due to its asynchronous nature, challenges with concurrency and race conditions still need to be addressed解决.
实际上,当线性一致性是必需的,或者在有许多数据约束(如唯一性检查)的情况下,“事件优先”方法很难实现。但在其他场景中但它确实可以大放异彩。然而,由于它的异步性质,并发和竞争条件的挑战仍然需要解决。
Consistency by design
设计一致性
There many ways to split the system into multiple services. We strive 努力to match separate microservices with separate domains. But how granular粒度 are the domains? Sometimes it’s hard to differentiate 区分domains from subdomains or aggregation roots. There is no simple rule to define your microservices split.
有许多方法可以将系统分成多个服务。我们努力将不同的微服务与不同的域相匹配。但是这些域有多细呢?有时很难将域与子域或聚合根区分开来。没有简单的规则来定义您的微服务拆分。
Rather than与其 focusing only on domain-driven design, I suggest to be pragmatic务实 and consider all the implications of the design options. One of those implications is how well microservices isolation 独立aligns with对齐 the transaction boundaries. A system where transactions only reside within microservices doesn’t require any of the solutions above. We should definitely consider the transaction boundaries事物边界 while designing the system. In practice, it might be hard to design the whole system in this manner, but I think we should aim to minimize最小化 data consistency challenges.
与其只关注领域驱动的设计,我建议采取务实的态度,并考虑所有设计选项的含义。其中一个含义是微服务隔离与事务边界的匹配程度。事务只驻留在微服务中的系统不需要上述任何解决方案。在设计系统时,一定要考虑事务边界。在实践中,可能很难以这种方式设计整个系统,但我认为我们的目标应该是尽量减少数据一致性的挑战。
Accepting inconsistency 接受不一致
While it’s crucial重要 to match the account balance, there are many use cases where consistency is much less important. Imagine gathering收集 data for analytics or statistics purposes. Even if we lose 10% of data from the system randomly, most likely the business value from analytics won’t be affected.
虽然与帐户余额匹配是至关重要的,但在许多用例中,一致性的重要性要小得多。比如,为分析或统计目的收集数据。即使我们随机丢失了10%的系统数据,从分析中获得的业务价值也很可能不会受到影响。
Which solution to choose
选择哪种解决方案
Atomic update of data requires a consensus共识 between two different systems, an agreement 协议if a single value is 0 or 1. When it comes to microservices, it comes down归结 to problem of consistency between two participants参与者 and all practical solutions follow a single rule of thumb经验法则:
数据的原子更新需要两个不同系统之间的协商一致,形成对某值为0或者为1的共识。当涉及到微服务时,它归结为两个参与者之间的一致性问题,所有实际的解决方案都遵循一个经验法则:
In a given moment, for each data record, you need to find which data source is trusted by your system
在给定的时刻,对于每个数据记录,需要找到可信的基准数据
The source of truth could be events, the database or one of the services. Achieving consistency in microservice systems is developers’ responsibility. My approach is the following:
Try to design a system that doesn’t require distributed consistency. Unfortunately, that’s barely possible几乎不可能 for complex systems.
Try to reduce the number of inconsistencies 不一致性by modifying one data source at a time.
Consider event-driven architecture. A big strength of event-driven architecture in addition to loose coupling松耦合 is a natural way of achieving data consistency by having events as a single source of truth or producing events as a result of change data capture.
More complex scenarios might still require synchronous calls between services, failure handling and compensations. Know that sometimes you may have to reconcile afterwards.
Design your service capabilities to be reversible可逆的, decide how you will handle failure scenarios and achieve consistency early in the design phase.
基准数据可以是事件、数据库或某个服务。在微服务系统中实现一致性是开发人员的责任。我的做法如下:
尝试设计一个不需要分布式一致性的系统。不幸的是,对于复杂的系统来说,这几乎是不可能的。
尝试通过一次修改一个数据源来减少不一致的数量。
考虑一下事件驱动的体系结构。除了松散耦合之外,事件驱动体系结构的一大优势是天然的支持基于事件的数据一致性,可以将事件作为基准数据,也可以由变更数据捕获(CDC)生成事件。
更复杂的场景可能仍然需要服务、故障处理和补偿之间的同步调用。要知道,有时你可能不得不在事后对账。
将您的服务功能设计为可逆的,决定如何处理故障场景,并在设计阶段早期实现一致性。
参考:
英文:https://ebaytech.berlin/data-consistency-in-microservices-architecture-bf99ba31636f

